
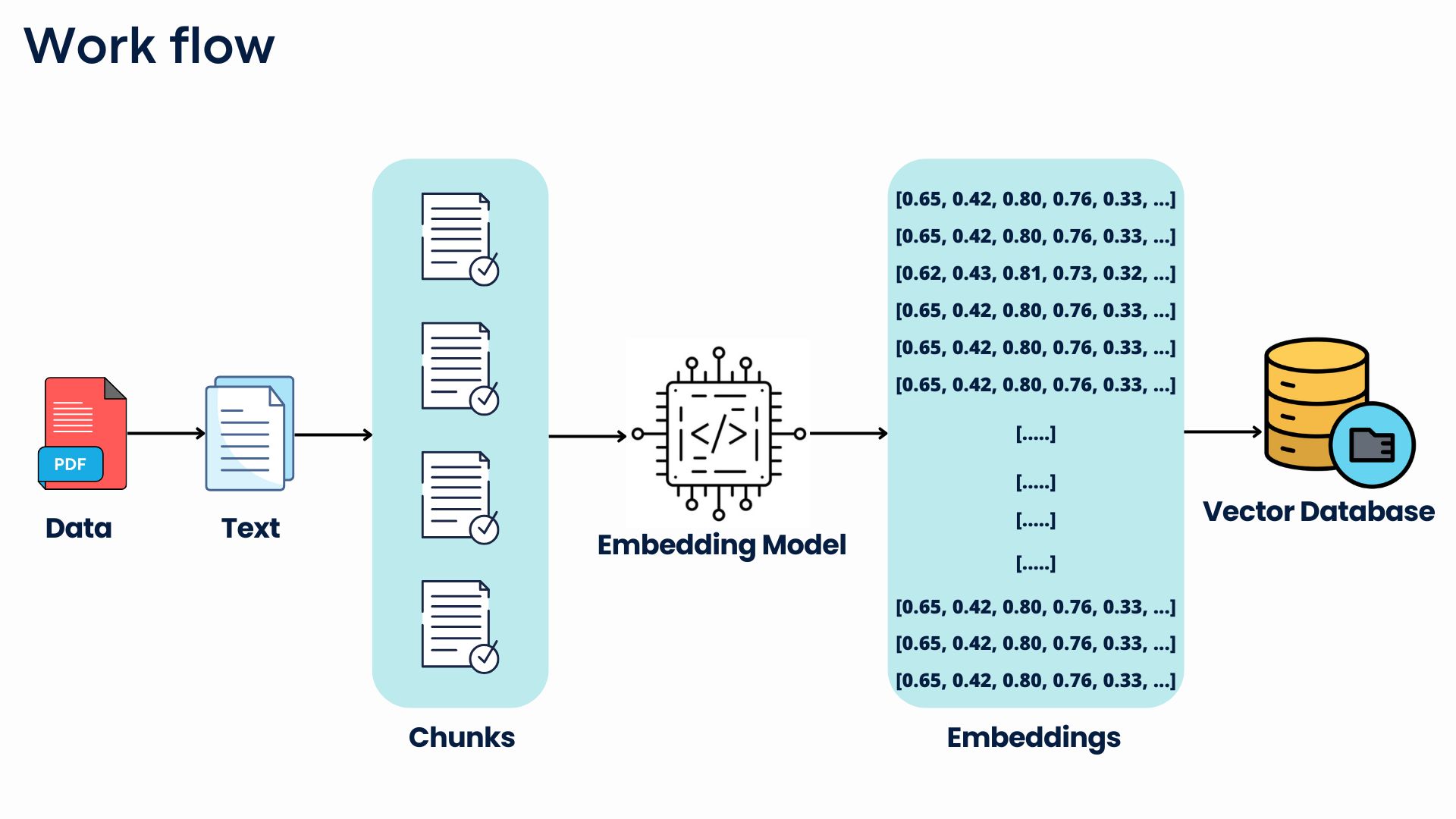
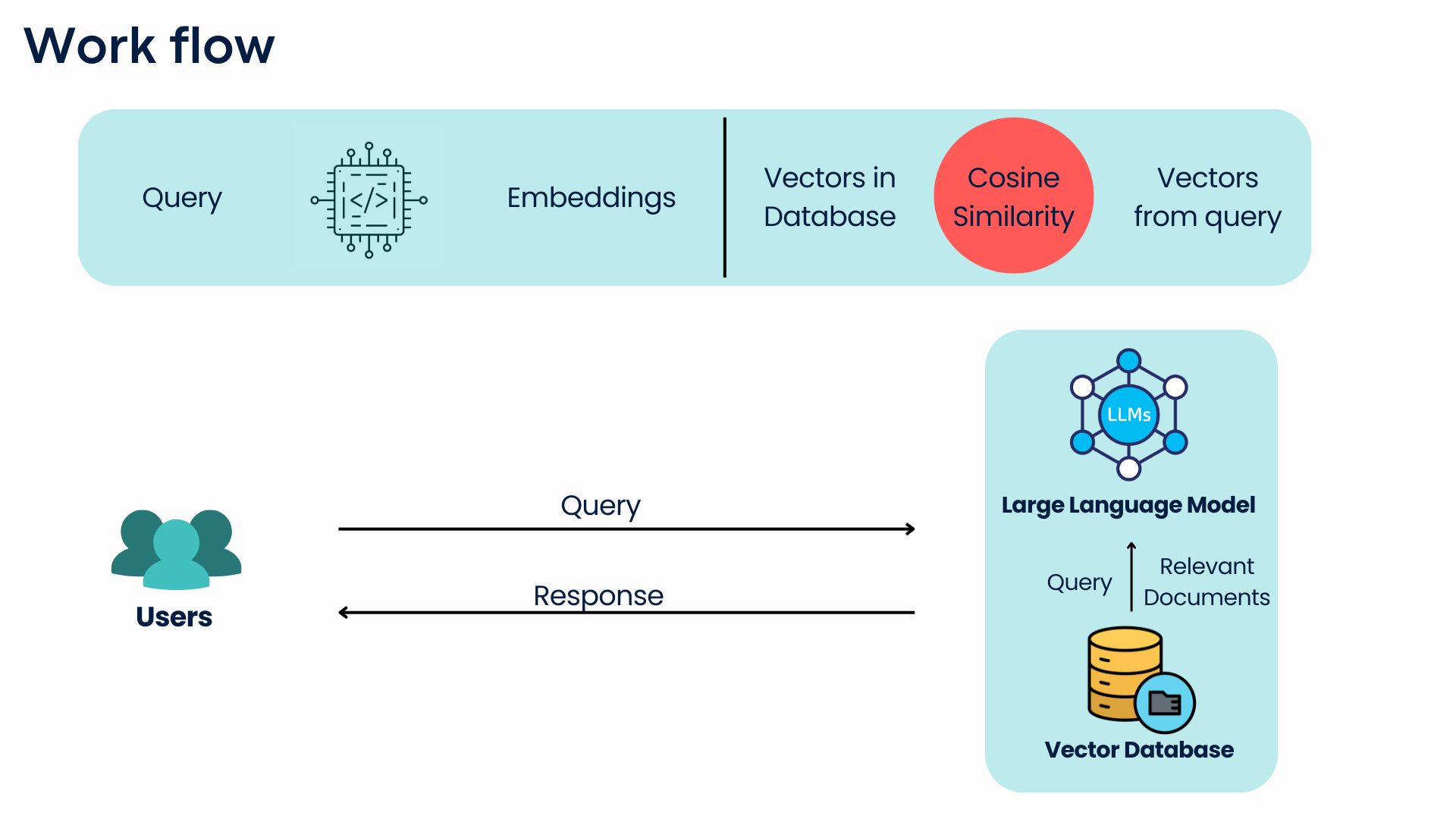
RAG (Retrieval-Augmented Generation) is a technique that makes AI models smarter by mixing two powerful methods: retrieving information and generating text. First, when the AI gets a question or task, it looks for relevant information from external sources, such as documents, databases, or websites. This ensures it has the most up-to-date and specific details. Then, the AI uses this information to create a response, combining what it already knows with the newly found data. This approach helps the AI provide more accurate, relevant, and reliable answers, especially for complex questions where it needs to reference fresh or detailed content that may not be part of its original training.
from langchain_community.document_loaders import PyPDFLoaderfrom langchain.text_splitter import RecursiveCharacterTextSplitterfrom langchain_google_genai import GoogleGenerativeAIEmbeddingsfrom langchain_chroma import Chromafrom langchain_google_genai import ChatGoogleGenerativeAIfrom langchain.chains import create_retrieval_chainfrom langchain.chains.combine_documents import create_stuff_documents_chainfrom langchain_core.prompts import ChatPromptTemplateThis code snippet imports various modules from the LangChain library, which is used for building AI applications that integrate external data and generative AI models. It includes tools for loading PDF documents (PyPDFLoader), splitting text (RecursiveCharacterTextSplitter), embedding data using Google Generative AI (GoogleGenerativeAIEmbeddings), and creating chains for retrieving and processing documents. These chains enable the use of AI models, like Google Generative AI (ChatGoogleGenerativeAI), to generate responses based on external knowledge sources, making it useful for tasks like document retrieval and AI-driven interactions.
This code snippet uses the PyPDFLoader to load a PDF file named "yolov9_paper.pdf". The loader.load() function extracts the content of the PDF into the variable data, which can then be processed or displayed as needed. The commented line # print(data) suggests that you could print the loaded content to view it. This process is helpful for extracting and working with text from PDF documents in an automated way.
loader = PyPDFLoader("yolov9_paper.pdf")data = loader.load()# print(data)text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000)docs = text_splitter.split_documents(data)# print(docs)In this code snippet, a RecursiveCharacterTextSplitter is created with a chunk_size of 1000 characters. This is used to split the previously loaded PDF data (data) into smaller chunks or documents for easier processing. The resulting chunks are stored in the docs variable. The comment # print(docs) indicates that the chunks can be printed for review or further analysis. This is useful for breaking large text data into manageable parts.
This code snippet first sets the GOOGLE_API_KEY for accessing Google Generative AI services. It creates a vector store (vectorstore) using Chroma, which takes the document embeddings generated by GoogleGenerativeAIEmbeddings. These embeddings help represent the document text for similarity search. The retriever is then created from the vector store to find the top 10 most similar documents using similarity search. Finally, a language model (llm) is initialized using the ChatGoogleGenerativeAI with the gemini-1.5-pro model, and the provided API key is used for querying the AI.
GOOGLE_API_KEY = "XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX"vectorstore = Chroma.from_documents(documents=docs, embedding=GoogleGenerativeAIEmbeddings(model="models/embedding-001", google_api_key=GOOGLE_API_KEY))# print(vectorstore)retriever = vectorstore.as_retriever(search_type="similarity")# print(retriever)llm = ChatGoogleGenerativeAI(model="gemini-1.5-pro",temperature=0,max_tokens=None,timeout=None, google_api_key=GOOGLE_API_KEY)user_query = input("Enter your question: ")# print(user_query)system_prompt = ("You are an assistant for question-answering tasks. ""Use the following pieces of retrieved context to answer ""the question. If you don't know the answer, say that you ""don't know. Use three sentences maximum and keep the ""answer concise."\n\n" {context}")This code snippet prompts the user for a question (user_query = input("Enter your question:"")) and sets a system_prompt which instructs the assistant on how to respond. The assistant is tasked with answering questions using retrieved context, keeping the response concise and within three sentences. If the answer is not known, the assistant will acknowledge that. The {context} is a placeholder for the retrieved information relevant to the question.
This code snippet uses the PyPDFLoader to load a PDF file named "yolov9_paper.pdf". The loader.load() function extracts the content of the PDF into the variable data, which can then be processed or displayed as needed. The commented line # print(data) suggests that you could print the loaded content to view it. This process is helpful for extracting and working with text from PDF documents in an automated way.
prompt = ChatPromptTemplate.from_messages( [ ("system", system_prompt), ("human", "{input}"), ])if user_query: question_answer_chain = create_stuff_documents_chain(llm, prompt) rag_chain = create_retrieval_chain(retriever, question_answer_chain) response = rag_chain.invoke({"input": user_query}) print(response["answer"])from langchain_community.document_loaders import PyPDFLoaderfrom langchain.text_splitter import RecursiveCharacterTextSplitterfrom langchain_google_genai import GoogleGenerativeAIEmbeddingsfrom langchain_chroma import Chromafrom langchain_google_genai import ChatGoogleGenerativeAIfrom langchain.chains import create_retrieval_chainfrom langchain.chains.combine_documents import create_stuff_documents_chainfrom langchain_core.prompts import ChatPromptTemplateloader = PyPDFLoader("yolov9_paper.pdf")data = loader.load()# # print(data)text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000)docs = text_splitter.split_documents(data)# # print(docs)GOOGLE_API_KEY = "XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX"vectorstore = Chroma.from_documents(documents=docs, embedding=GoogleGenerativeAIEmbeddings(model="models/embedding-001", google_api_key=GOOGLE_API_KEY))# # print(vectorstore)retriever = vectorstore.as_retriever(search_type="similarity", search_kwargs={"k": 10})# print(retriever)llm = ChatGoogleGenerativeAI(model="gemini-1.5-pro",temperature=0,max_tokens=None,timeout=None, google_api_key=GOOGLE_API_KEY)# print(llm)user_query = input("Enter your question: ")# print(user_query)system_prompt = ( "You are an assistant for question-answering tasks. " "Use the following pieces of retrieved context to answer " "the question. If you don't know the answer, say that you " "don't know. Use three sentences maximum and keep the " "answer concise." "\n\n" "{{context}}")prompt = ChatPromptTemplate.from_messages( [ ("system", system_prompt), ("human", "{input}"), ])if user_query: question_answer_chain = create_stuff_documents_chain(llm, prompt) rag_chain = create_retrieval_chain(retriever, question_answer_chain) response = rag_chain.invoke({"input": user_query}) print(response["answer"])




